Welcome to the award-winning BU Research Blog!
Our research shapes and changes the world around us, providing solutions to real-world problems and informing the education we deliver.
Click here to view the full blog, or browse the categories below and with the menu above.
BU staff can login below:

Don’t miss a post!
Subscribe for the BU Research Digest, delivered freshly every day.
Funding opportunities
View current funding opportunities »- BU ECRN Funding call NOW OPEN – Deadline 26th April
- BU ECRN Funding call NOW OPEN
- Q&A event: applying for the ESRC Festival of Social Science
- New seed fund for public engagement with research: apply now
- Open Call for HEIF Knowledge Exchange Project Applications 2024
- Leverhulme Research Centres – Internal Expressions of Interest February 2024
BU research
 Funding to compare imaging modalities for liver cancer detectionBournemouth University researchers at the Institute of Medical Imaging and Visualisation (IMIV) will contribute to a new national study evaluating... Read more »
Funding to compare imaging modalities for liver cancer detectionBournemouth University researchers at the Institute of Medical Imaging and Visualisation (IMIV) will contribute to a new national study evaluating... Read more » Conversation article: London Marathon – how visually impaired people runAhead of the London Marathon this weekend, Dr Ben Powis co-authors this article for The Conversation which explains the variety... Read more »
Conversation article: London Marathon – how visually impaired people runAhead of the London Marathon this weekend, Dr Ben Powis co-authors this article for The Conversation which explains the variety... Read more »- 2nd HSS PGR Conference – submission deadline 19th AprilLast chance to submit… The Conference Committee welcome all PGRs in HSS to submit an abstract to present at the... Read more »
- BU ECRN Funding call NOW OPEN – Deadline 26th AprilThe RKEDF and BU ECRN are delighted to offer funding (up to £500) to organise an event, roundtable, meeting, training,... Read more »
- ECRN – The Conversation Media Training Are you an academic, researcher or PhD candidate who would like to build a media profile and take your... Read more »
- New Intention to Bid (ItB) FormSince the introduction of workstreams in October 2022, the Transformation team and the Research Development and Support (RDS) team have... Read more »
international
PG research
Other services







Research lifecycle
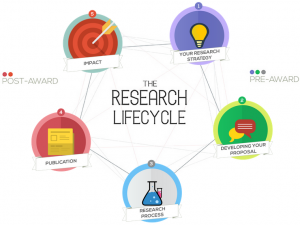 Our Research Lifecycle diagram is a jazzy interactive part of the BU Research Blog that shows the support and initiatives that are available to staff and students at each stage of the research lifecycle.
Our Research Lifecycle diagram is a jazzy interactive part of the BU Research Blog that shows the support and initiatives that are available to staff and students at each stage of the research lifecycle.